TCP--常见重传机制
在传输包的过程中,会有好多问题导致服务端收不到包,比如说包丢失、网络慢等等。我们就需要一种机制来重传服务端没有收到的包。
常见的超时重传机制有。
- 超时重传
- 快速重传
- SACK
- D-SACK
一、超时重传
服务端每次收到客户端的一个包就会发回一个ACK包,表示确认。客户端从发包开始启动计时器,如果经过一段时间客户端没有收到这个ACK包,客户端就会重传丢失的包,这个时间叫做RTO。\
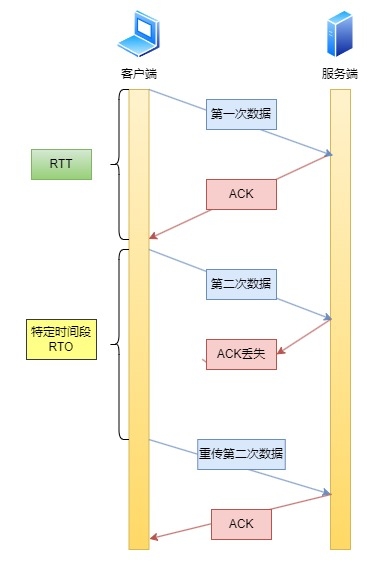 \
\
那这个RTO设置多长时间比较好呢?\
这里先说一个RTT时间,RTT时间就是发送一个数据到接收到确认信息的时间,相当于正常来说从发送数据开始到该收到确认信息的时间。\
那RTO和RTT之间的大小关系是怎样的呢,下面我们给个图更方便的看一点。
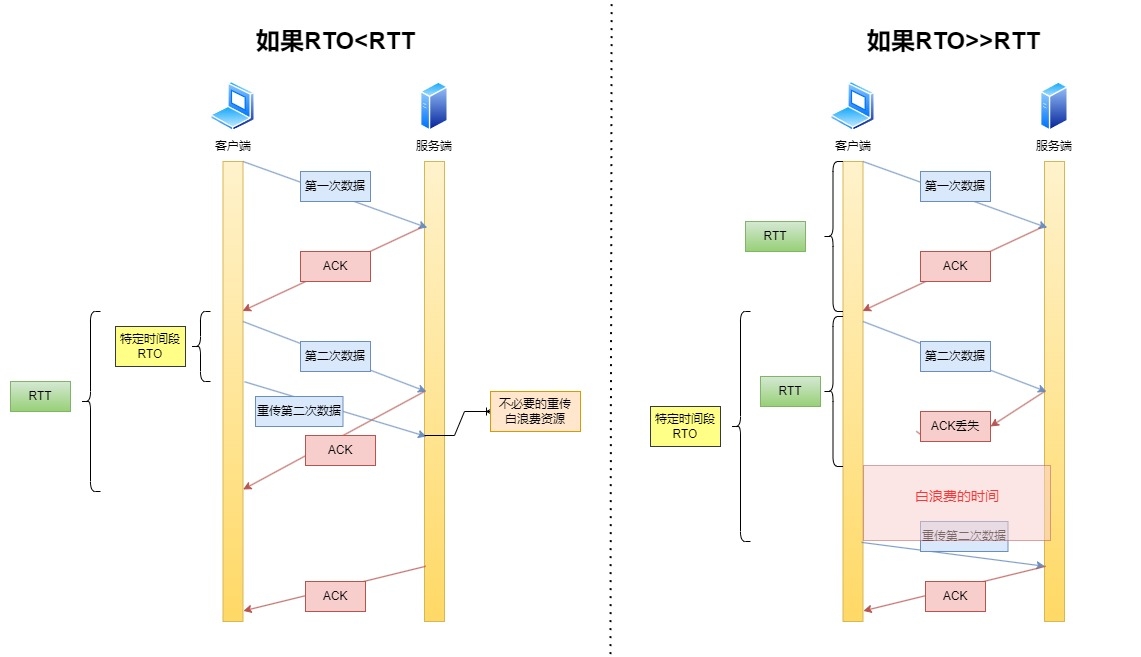
如果RTO<RTT,那么就会发生不必要的重传,浪费计算机资源。\
如果RTO远大于RTT,那么中间就会等待不必要的的时间浪费。\
那么怎么样好呢,其实就是RTO刚好比RTT大一点,但又不是大很多。类似下面这样的。\
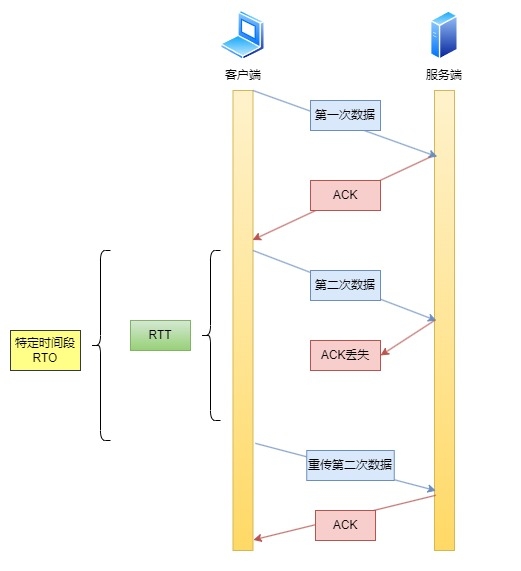 \
\
那有人就说了,那测试一个RTT出来,然后加个一个t就好了。其实没这么简单,网络都是在波动的,所以RTT时间也是在不断波动的,所以我们的RTO也是在不断波动的,具体的RTO如何计算,大家可以看其他的博客,这里不在细讲了。\
Linux中的超时时间是倍增的,如果第一次发包没有收到ACK,那么经过一个RTO时间重传。如果这个重传的包依旧没有收到ACK,那么就是等待两个RTO时间再进行重传,每次都会乘以2。
二、快速重传
快速重传是基于数据的一种重传方式。\
.webp)
服务端每次收到数据后,就会返回一个ACK(确认序列号)表示下次希望收到的数据的序号,并且表示该序号之前的数据都已经成功接受。\
TCP默认是累计确认机制,当中间有包乱序到达了,TCP只会反复确认最后一个按序到达的数据,TCP只能知道下一个数据没有按时达到,之后的数据怎么样了并不知道。
如图所示,第二个数据丢失了,服务端一直返回ACK2(因为一直没有收到第二个数据),当客户端收到3次同样的ACK后,客户端就会重传丢失的那个数据。然后服务端传回一个ACK6,表示6之前的数据都已经成功接受了。客户端收到3个相同的ACK后,就在超时重传时间之前进行重传。\
但是这样还是有个问题,就是重传的时候,是重传一个数据,还是重传所有数据呢。\
比如说数据2、3都丢失了,因为ACK只能表示下一次应该重传的一个数据,不能表示多个数据,所以即便数据3也丢失了,它依然是返回ACK2。\
如果重传2号数据,那3号数据也丢失了。如果都重传一次,显然是一次不必要的资源浪费。\
这就引出了我们的下一个知识点SACK。
三、SACK 选择性确认
保存丢失段后面成功到达的序号段,确定缺失的序号段。\
我们在返回的包里加一个SACK(以一定格式存储在TCP头的选项中),SACK表示已经接受到的数据的序列号的范围。前提是双方都支持了SACK。我们看下图。\
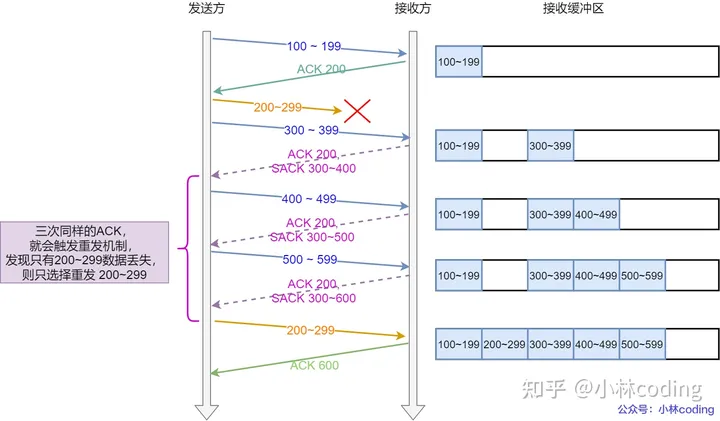 \
\
我们从图中可以看到,200~299的数据丢失了,之后的数据正常到达服务端,SACK保存了后面到达序号的范围,然后告诉客户端后面这些数据正常到达了。\
这里ACK和SACK之间有一段空白,说明这些数据丢失了,要重传这一段数据。
四、D-SACK
表示重复收到了数据。\
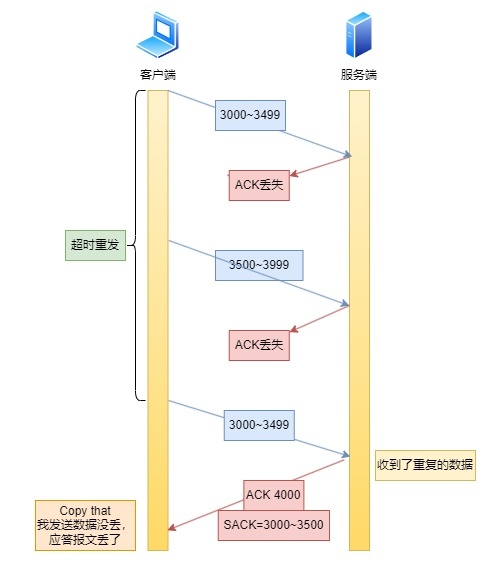 \
\
最后服务端返回了一个SACK3000~3500,表示3000到3500的数据都被接受了,ACK4000表示你该从4000开始发送数据了,这里的SACK其实就是D-SACK。
作者:徐锦桐
链接:https://www.xujintong.com/2023/10/02/54/
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)